




Assume you're a well-known author signing books at a book signing event. A throng of people has gathered to greet you. Since only one autograph can be done at a time, the organizers let people in one by one. You ask the next person to come forward when you sign someone's book. What if the organizers let everybody in at once? Of course, it will be complete chaos! You'll try and sign everyone's books as fast as possible, but you'll eventually get overwhelmed and tired, and you'll have to leave the event early.
It is much more efficient to have an orderly queue of people and to take your time to sign each book. Because you always ask for the next person to come forward, you are in control of the amount of work you have to do and it is much easier to keep going. Maybe you won’t get that tired, so you decide to stay at the event longer and make sure everyone gets an autograph. This is in fact an example of handling back-pressure in real life.
How does this translate in programming? The GenStage library works like the well-organized book event we just described. The system will process only the amount of work it can handle at a given time, just like the famous writer from our example. If the system has free capacity it will politely ask for more work and wait for it.
This little change in our mindset has a big impact. It allows one to create dynamic data pipelines that self-regulate to make the maximum use of the available resources.
GenStage was originally developed by José Valim, the creator of Elixir, and released in July 2016. As he described it in the official announcement: “GenStage is a new Elixir behavior for exchanging events with back-pressure between Elixir processes.”
The GenStage behavior, as its name suggests, is used to build stages. Stages are also Elixir processes and they’re our building blocks for creating data processing pipelines. Stages are simple but very powerful. They can receive events and use them to do some useful work. They can also send events to the next stage in the pipeline. You can do that by connecting stages to each other, creating something like a chain, as you can see here:
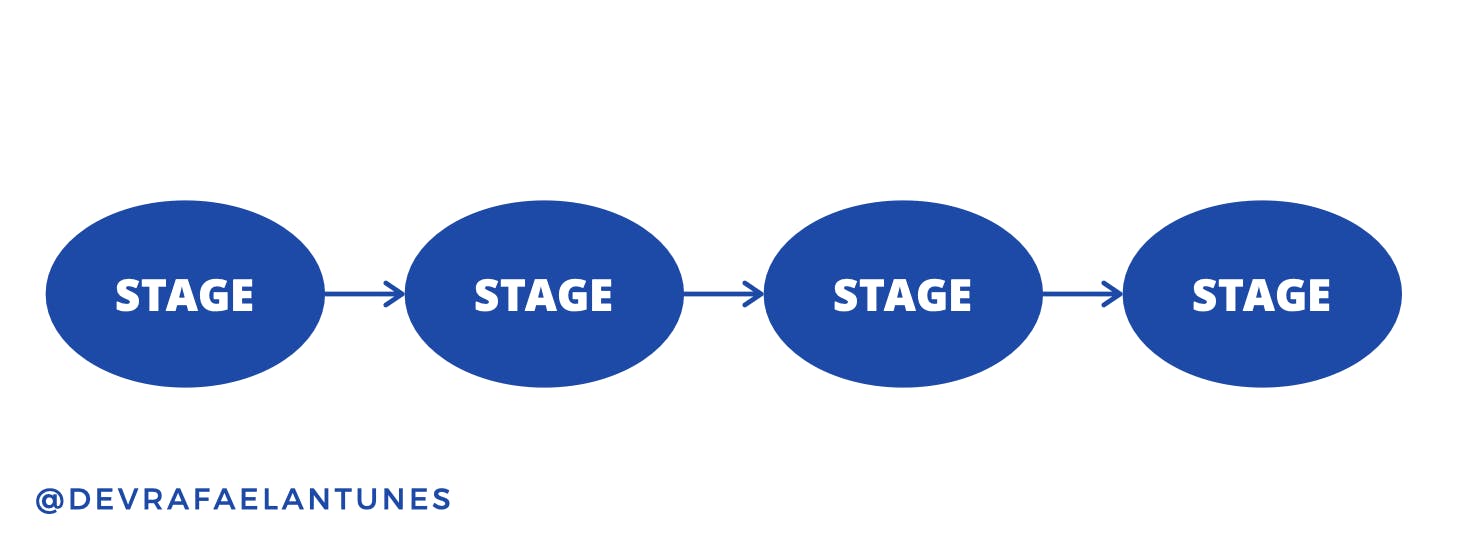
A stage can also have multiple instances of itself. Since stages are processes, this effectively means running more than one process of the same stage type. In practice, different problems require different solutions, so your data processing pipeline could end up looking completely different.
Stages are very flexible and can be used in a variety of ways. However, their most important feature is back-pressure. Although events move between stages from left to right on our diagram, it is actually the last stage in the pipeline that controls the flow. This is because the demand for more events travels in the opposite direction—from right to left. This figure shows how it works:
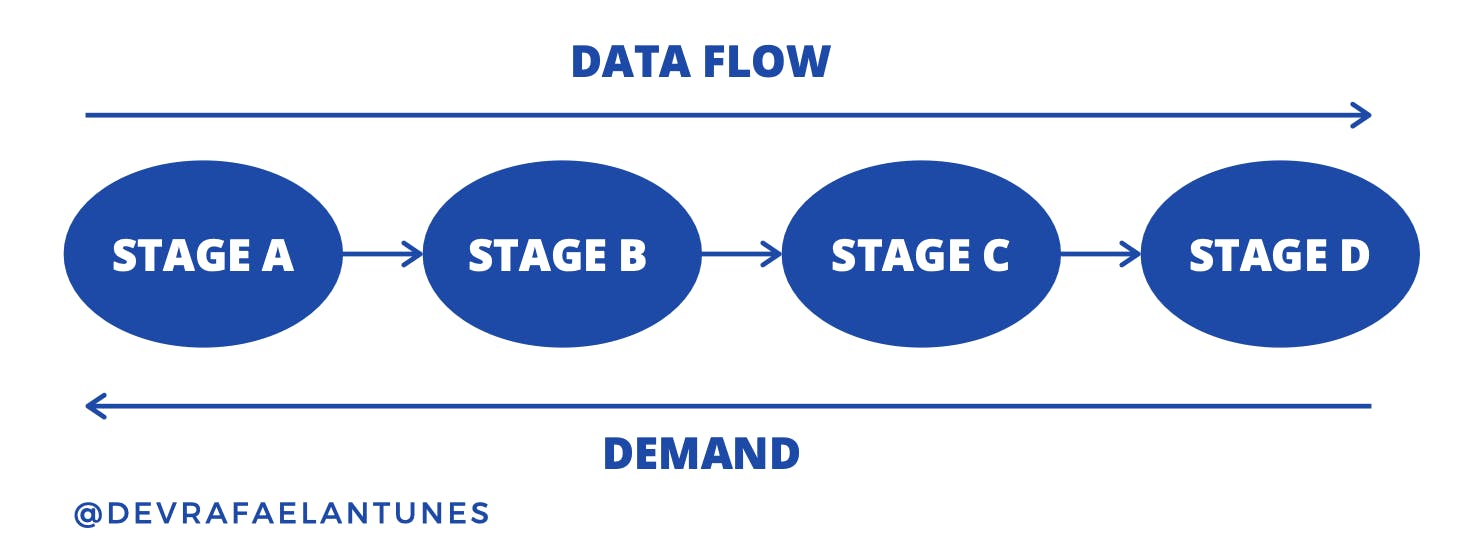
Stage D has to request events from Stage C, and so on, until the demand reaches the beginning of the pipeline. As a rule, a stage will send demand for events only when it has the capacity to receive more. When a stage gets too busy, demand will be delayed until the stage is free, slowing down the flow of data.
Connecting stages is easy, but first, you need to know what stages to use. There are three different types of stages available to us: producer, consumer, and producer-consumer. Each one plays a certain role. Let’s briefly cover each type of stage.
The Producer
- At the beginning of a data processing pipeline there is always a producer stage since the producer is the source of data that flows into the pipeline. It is responsible for producing events for all other stages that follow.
The Consumer
- Events created by the producer are received by the consumer stage. A consumer has to subscribe to a producer to let them know they’re available and request events. Consumer stages are always found at the end of the pipeline.
The Producer-Consumer
- Although having a producer and a consumer is already very useful, sometimes we need to have more than two stages in our pipeline. The producer-consumer stage has the special ability to produce and consume events at the same time. A useful analogy to a producer-consumer is the restaurant. A restaurant serves meals (producer) but in order to cook the meals, it needs ingredients sourced from its suppliers (acting as a consumer). In a nutshell, producer-consumers are the middle-man in our data processing pipelines.
Complex use cases may require a data processing pipeline with a consumer stage, one or more producers, and several producer-consumers in-between.
The following figure illustrates the simplest data pipeline we can create using GenStage:
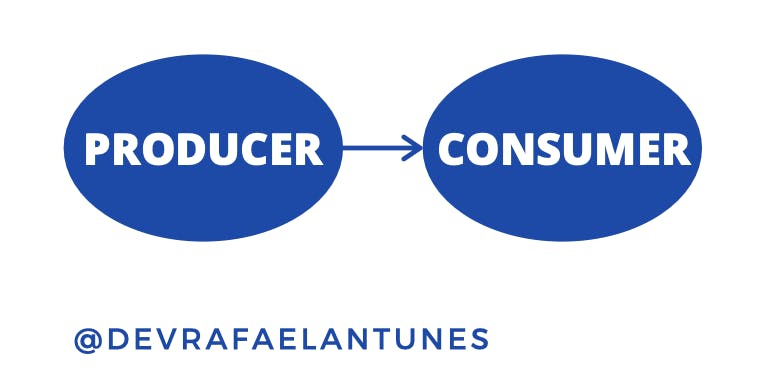
It has just a single producer and a consumer.
Although slightly intimidating at first, GenStage is a brilliant tool that makes other programming languages jealous of Elixir. Of course, as José Valim has pointed out many times, none of it would be possible without Erlang’s rock-solid OTP serving as a foundation.
Working with GenStage could be challenging. In order for your data processing pipeline to work, everything has to be configured and set up correctly. To achieve the desired level of concurrency, you may have to create more than a few types of stages. Often this makes GenStage a less appealing choice for more common tasks and problems, especially in teams less experienced with it.
To conclude, when working on more complex tasks, multi-stage pipelines can help model and tackle potential challenges. You can use and adapt these techniques to build resilient and scalable systems that perform well under increased workloads. GenStage is very versatile and can be configured in many different ways to solve an endless variety of problems, so I would encourage you to check GenStage’s official documentation and explore further what’s available.